
AI cybersecurity tools and platforms can help teams cut noise, spot attacks earlier, and respond faster, but in 2026 the bigger win is choosing products that fit your detection and response workflow instead of stacking more “smart” dashboards.
If you feel buried in alerts, vendor pitches, and half-integrations, you are not alone, many security programs are running a mix of cloud, SaaS, endpoints, and legacy network controls that do not share context well. AI can close gaps, but only when the underlying telemetry is clean and the operating model is realistic.

This guide focuses on what to use in 2026, what to skip, and how to test claims quickly. Expect practical checkpoints for machine learning threat detection software, an automated incident response platform, AI-powered SIEM integration, and the areas where “AI” often becomes an expensive rounding error.
What changed in 2026: AI is everywhere, outcomes are not
Most vendors now ship some form of AI, and many buyers assume that means “better detection.” In practice, the difference shows up in three places: faster triage, better correlation, and fewer manual steps during containment.
According to NIST, strong cybersecurity outcomes still depend on risk management fundamentals like asset visibility, secure configuration, and continuous monitoring, AI helps, but it cannot replace those controls when they are missing.
So when you evaluate AI cybersecurity tools and platforms, treat AI as an acceleration layer on top of data quality, process maturity, and integrations. If those basics are shaky, the model will look impressive in demos and disappointing in production.
Where AI actually helps: the 7 use cases that tend to pay off
Not every “AI feature” deserves budget, but a few patterns keep showing up as useful across industries, especially for lean SOC teams and hybrid environments.
- Machine learning threat detection software for finding low-and-slow behavior that rule-based alerts miss, especially privilege misuse and lateral movement.
- Behavioral analytics for user activity that flags unusual login paths, impossible travel, data access spikes, or risky app consent patterns in SaaS.
- Endpoint detection and response with AI to prioritize suspicious process trees and reduce “benign-but-weird” endpoint alerts.
- Network anomaly detection solution that baselines east-west traffic and highlights new protocols, beaconing patterns, or unusual DNS behavior.
- Phishing detection using natural language processing to catch lookalike tone, intent, and social engineering patterns beyond simple keyword checks.
- Ransomware prevention AI engine that recognizes early encryption behavior, shadow copy tampering, and mass file rename patterns on endpoints and servers.
- Cloud workload protection with AI for container and workload drift, suspicious runtime behavior, and risky IAM patterns tied to workload identity.
One practical takeaway: AI cybersecurity tools and platforms work best when they have a tight feedback loop, the team labels outcomes, tunes policies, and the product learns what “normal” means in your environment.
What to skip (or at least down-prioritize) when budgets are tight
Some categories look good on slides but often under-deliver unless your program is already mature. These are not “never buy,” they are “buy last, after the plumbing works.”
- Standalone AI “alert summarizers” with limited access to raw telemetry, they may rephrase alerts without improving decisions.
- Auto-remediation everywhere on day one, broad quarantine and account disable workflows can create business outages if logic is wrong.
- Black-box scoring that cannot explain why something is risky, this slows analyst trust and makes audits harder.
- Tools that “replace the SIEM” but still require SIEM-like data onboarding and parsing effort, you may end up doing the same work twice.
If a vendor cannot show how their model behaves under drift, noisy logs, or partial visibility, consider that a yellow flag. According to CISA, improving resilience often means focusing on visibility, secure configuration, and response readiness, shiny detection alone rarely fixes systemic gaps.
Quick evaluation checklist: how to tell “useful AI” from “AI theater”
Most teams do not need a six-month bake-off to get signal. You can pressure-test AI cybersecurity tools and platforms with a short, structured pilot.
Data and integration checks (before any scoring)
- Can it ingest the telemetry you already trust, endpoint, identity, email, cloud, and network, without custom work that only the vendor can maintain?
- Does it support AI-powered SIEM integration both ways, read context in, and write decisions back out?
- Will it work with your security orchestration and automation tools, or does it require its own parallel playbook system?
Model transparency checks (during the pilot)
- Can analysts see the evidence, timeline, and features that drove a detection, not just a risk number?
- Can you tune sensitivity by environment, for example, dev vs prod, executives vs general users?
- Does it measure false positives in a way you can validate, with labels and outcomes?

Operational checks (the part many teams miss)
- Who owns tuning, SecOps, IT, or the vendor, and how often will you review changes?
- What happens when the tool is wrong, is there a safe rollback and an audit trail?
- Does it reduce mean time to acknowledge and contain, or just generate “better looking” alerts?
What to choose in 2026: a practical “stack map” by need
Rather than naming brands that may change quickly, it is more useful to map capabilities to your constraints. The table below shows common starting points and what “good” tends to look like in 2026.
| Need | What to look for | Common pitfall | Best-fit teams |
|---|---|---|---|
| Threat detection across tools | Strong parsing, correlation, and AI-powered SIEM integration | Buying “AI SIEM” without data hygiene | Mid-large orgs with diverse telemetry |
| Endpoint control | Endpoint detection and response with AI, clear investigation graphs, safe isolation controls | Too many duplicate endpoint agents | Any org with laptops and servers |
| Faster containment | Automated incident response platform with approvals, guardrails, and logging | Over-automation causing outages | Teams with repeatable playbooks |
| Email and user risk | Phishing detection using natural language processing plus DMARC and user reporting workflow | Relying on NLP while ignoring configuration | Organizations with heavy email use |
| Cloud runtime risk | Cloud workload protection with AI, workload identity context, runtime signals | Only scanning images, ignoring runtime | Cloud-native and hybrid cloud teams |
| Network blind spots | Network anomaly detection solution that explains anomalies and supports tuning | Anomaly spam with no context | OT, campus networks, large east-west traffic |
| Ransomware readiness | Ransomware prevention AI engine plus backup immutability and recovery testing | Thinking “AI” replaces recovery planning | Any org with file shares and critical apps |
If you are trying to simplify, pick one “center of gravity” for triage, then integrate everything else around it. Many environments land on SIEM or XDR as that hub, but the right answer depends on how your team works and what telemetry you can maintain.
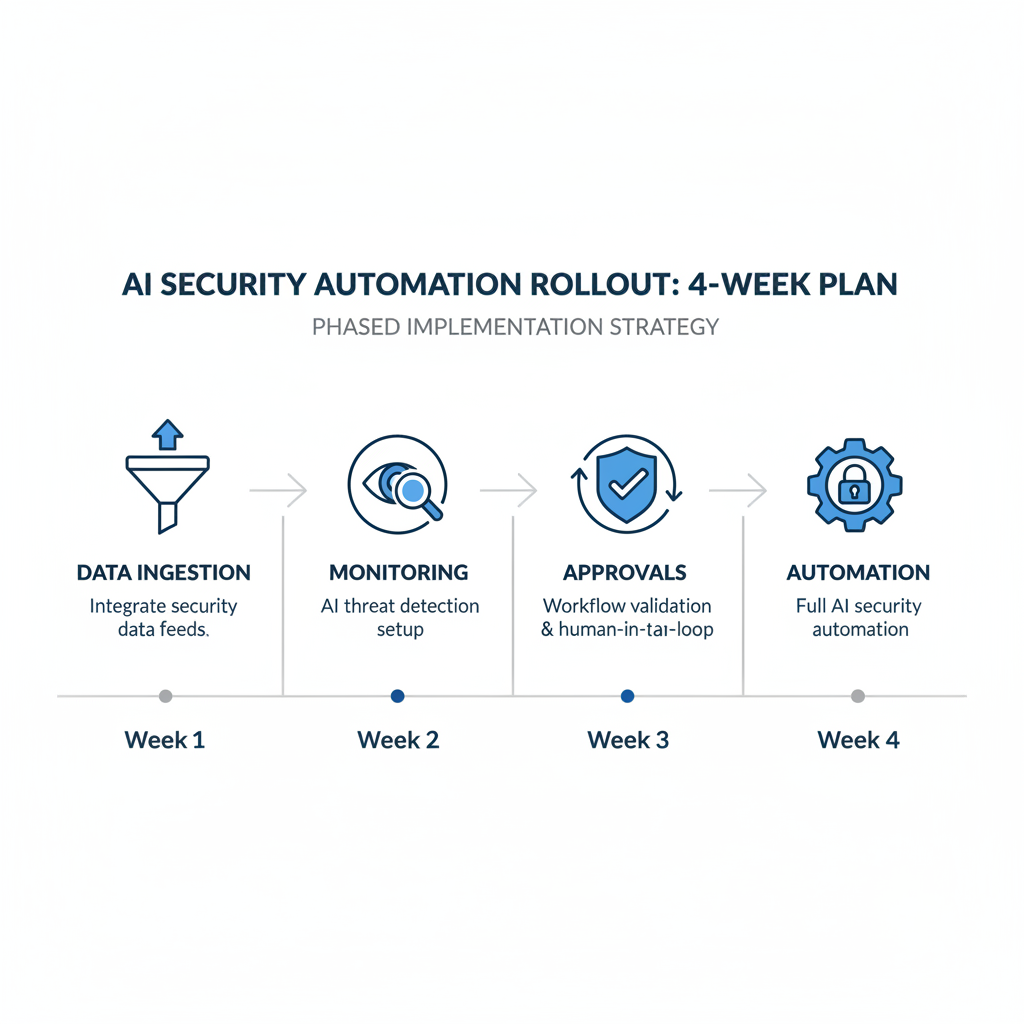
Hands-on rollout plan: 30 days to measurable improvement
You do not need perfection to get value, but you do need a plan that protects production and builds analyst trust.
- Week 1: inventory data sources, confirm log quality, define 5–10 high-impact detections you want improved, for example suspicious OAuth grants, impossible travel with token reuse, endpoint encryption behavior.
- Week 2: run the tool in monitor mode, label outcomes daily, and track where alerts come from, identity, endpoint, cloud, email.
- Week 3: add response actions with approvals, start with reversible steps like ticket creation, enrichment, tagging, and temporary containment.
- Week 4: expand to a limited set of auto-actions, document exceptions, and hand off a tuning cadence to your operational owner.
Key point: you are not “proving the AI,” you are proving that your team can run it safely. If the pilot cannot show fewer escalations or faster containment, it may be a fit issue rather than a model issue.
Common mistakes that quietly kill ROI
These are the patterns that make teams feel like AI “doesn’t work,” when the real issue is usually operational.
- Ignoring identity context: detections get sharper when you include IAM, MFA, device posture, and session risk signals.
- Buying overlapping tools: two products may detect the same thing and double your noise, consolidation often beats layering.
- No ownership: if nobody owns tuning, your false positives creep up until analysts mute alerts.
- Skipping response design: if an alert cannot drive a decision, it becomes expensive trivia.
- Assuming “AI replaces training”: analysts still need playbooks, escalation rules, and time to learn new investigation views.
When you should bring in outside help
Some rollouts are risky enough that you should consider a security consultant, MSSP, or incident response retainer, especially if you operate regulated environments or you already have active compromises.
- You plan to enable broad auto-containment across identity, endpoints, and cloud, and outages would be costly.
- You suspect ransomware pre-positioning, repeated credential theft, or persistent access, and need independent validation.
- Your logging is inconsistent, and you need architecture help before any machine learning threat detection software can produce reliable outcomes.
This is not about spending more, it is about reducing the chance that automation makes the wrong change at the wrong time. In many cases, a short engagement to design guardrails and run tabletop exercises pays back quickly.
Conclusion: pick fewer tools, demand better integration
The most reliable 2026 strategy is boring in a good way: choose AI cybersecurity tools and platforms that plug into your data, explain their reasoning, and improve response speed without risky automation. If you do two things this week, define the top five incidents you want to handle better, then run a pilot that measures time saved and false positives, not demo polish.
If you want a simple next step, list your current telemetry sources, decide which system is your triage hub, and only then evaluate add-ons like behavioral analytics for user activity or a network anomaly detection solution.