
Open-Weight Models are AI models whose trained parameters (the “weights”) are shared so you can run inference, fine-tune, and deploy them on your own infrastructure, usually under specific license terms. If you have ever tried to move from “cool demo” to “reliable product,” this detail matters more than most people expect.
A lot of teams assume “open-weight” means “open source AI,” and then get surprised by licensing limits, missing training data details, or model cards that do not answer enterprise questions. The practical question is not philosophical, it’s operational: what are you allowed to do, and what will it cost to run safely at scale.
This guide breaks down what open weights really give you, where the traps tend to be, and how to pick an open weight LLM for enterprise use without overpromising to legal, security, or product leadership.
What “Open-Weight” Actually Means (and What It Doesn’t)
In plain terms, open weights mean you can download the model parameters and run the model yourself. That typically enables open weight model inference without calling a hosted API, and it also enables customization through open weight model fine tuning if the license and tooling allow it.
What it often does not mean: full transparency into training data, a truly permissive license, or community governance. Some releases include training code, some do not. Some provide evaluation details, some give only a headline benchmark table.
- Weights available: you can run the model locally or in your cloud account.
- Training data may be closed: you might not know what went in, which affects risk reviews.
- License varies: commercial use may be allowed, restricted, or require conditions.
According to NIST, trustworthy AI involves considerations like validity, reliability, safety, security, and accountability. In real procurement, open weights help with control and inspection, but they do not automatically satisfy those properties.
Open Weight Model vs Open Source AI: The Practical Distinction
The term “open source” has a specific meaning in software, while “open-weight” is more of an AI distribution pattern. The difference becomes obvious when procurement asks: “Can we ship this in a paid product, and can we modify it?”
Here’s a practical comparison you can reuse internally.
| Topic | Open-Weight Models | Open Source AI (strict sense) |
|---|---|---|
| What’s shared | Model weights (sometimes code + docs) | Source code under OSI-style licenses |
| Commercial rights | Depends on license, can be limited | Usually clearer, permissive options exist |
| Auditability | Runtime behavior inspectable; training data often unclear | Code inspectable; data/model artifacts vary |
| Typical enterprise friction | License, safety, support, hosting cost | Maintenance burden, security hardening, governance |
So when someone asks “open weight model vs open source ai,” the honest answer is: open weights give you deployment control, while open source usually speaks to licensing and modifiability of code. They overlap sometimes, but not reliably.
Open Weight Model Examples You’ll Hear About (and How to Read Them)
When people ask for open weight model examples, they usually mean families of LLMs released with downloadable checkpoints and a model card. The names change quickly, and you should treat any list as time-sensitive, but the evaluation approach stays stable.

Instead of anchoring on a single model name, use these questions to interpret any candidate:
- Checkpoint quality: Is it a base model, an instruction-tuned model, or both?
- Model card depth: Does it describe limitations, intended use, and evaluation scope?
- Ecosystem: Are there stable inference libraries, quantization recipes, and deployment references?
- Operational fit: Does it support your context length, latency target, and hardware budget?
According to OpenSSF, software supply chain security depends on provenance and integrity. For open-weight releases, you want similar thinking: verified downloads, checksums, and a clear artifact trail.
Benchmarks and Evaluation: What to Trust, What to Verify
Open weight model benchmarks can be useful, but they are not a purchase order. Many benchmarks reflect academic tasks, while your real workload might be customer support, retrieval-augmented generation, or code assistance with strict formatting.
What tends to work in practice is a two-layer evaluation plan: a fast gate for obvious misses, then a task-specific suite that mirrors production prompts.
A realistic evaluation checklist
- Capability fit: Does it follow instructions, cite sources when asked, and keep stable output structure?
- Regression risk: Do changes in quantization or serving stack alter outputs?
- Safety behavior: How does it respond to policy-violating or sensitive requests?
- RAG compatibility: Does it use retrieved context well, or hallucinate past it?
- Latency and cost: Tokens/sec on your hardware, not the author’s hardware.
According to NIST, AI systems should be evaluated across their full lifecycle. For an open weight model evaluation, that typically means repeating tests after fine-tuning, after quantization, and again after you add tools or retrieval.
Licensing: Where Most Teams Lose Time
Open weight model licensing is where “it’s open” turns into “it’s complicated.” Some licenses allow broad commercial use, others restrict certain industries, user counts, or require attribution and pass-through terms. If you are building for enterprise customers, legal review is not optional.
What to capture in your internal decision doc:
- Commercial usage rights: Is revenue-generating use allowed without separate agreements?
- Redistribution: Can you ship the weights in an on-prem product, or only use internally?
- Derivative models: Are fine-tuned checkpoints considered derivatives, and can they be distributed?
- Acceptable use policy: Any restricted domains or prohibited use cases?
- Indemnity and liability: Usually limited or absent, plan accordingly.
If anything looks unclear, treat it as unclear. In many organizations, the fastest path is to shortlist models with licenses that your legal team already recognizes, then evaluate capability second.
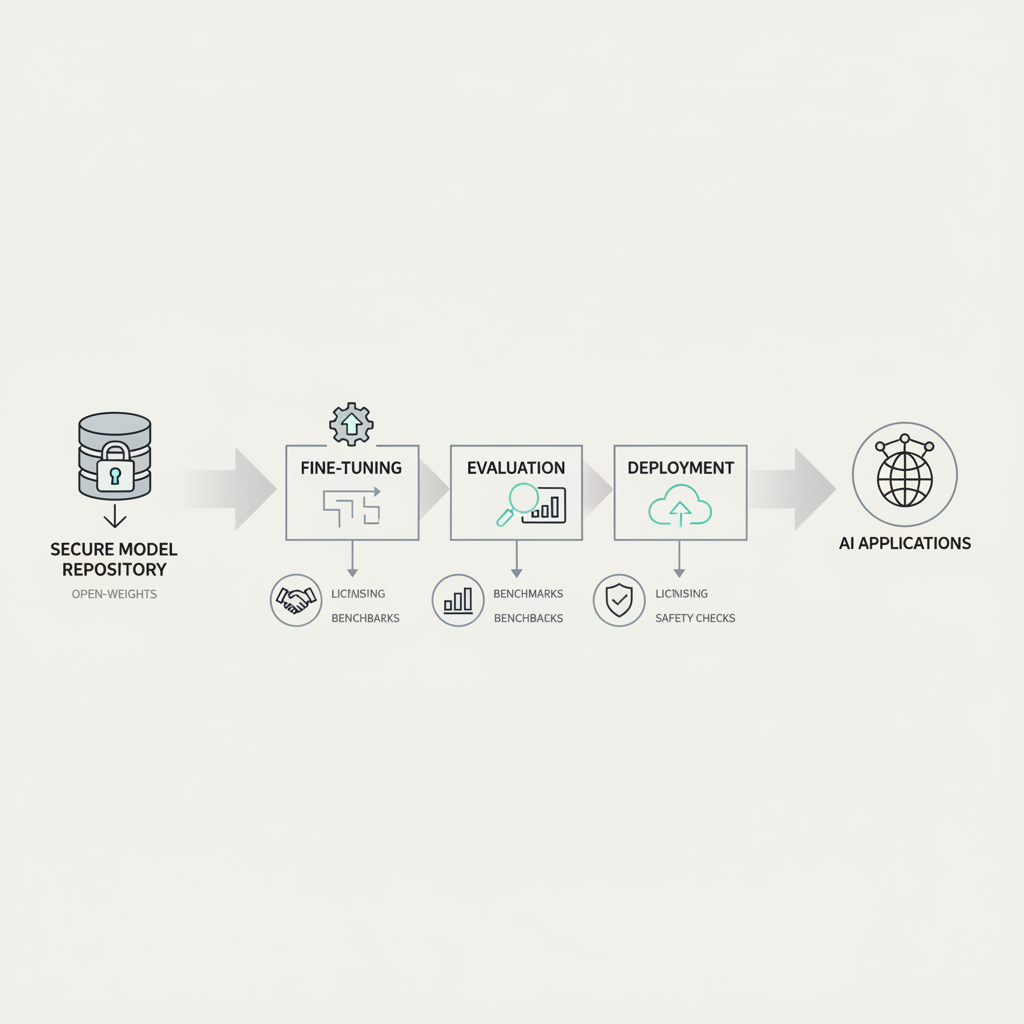
Fine-Tuning, Inference, and Deployment: A Practical Path
Most teams do not need to fine-tune on day one. You can often get far with prompt engineering plus retrieval. But when you need stable tone, domain vocabulary, or stricter formatting, open weight model fine tuning becomes attractive.
Step-by-step, what usually works
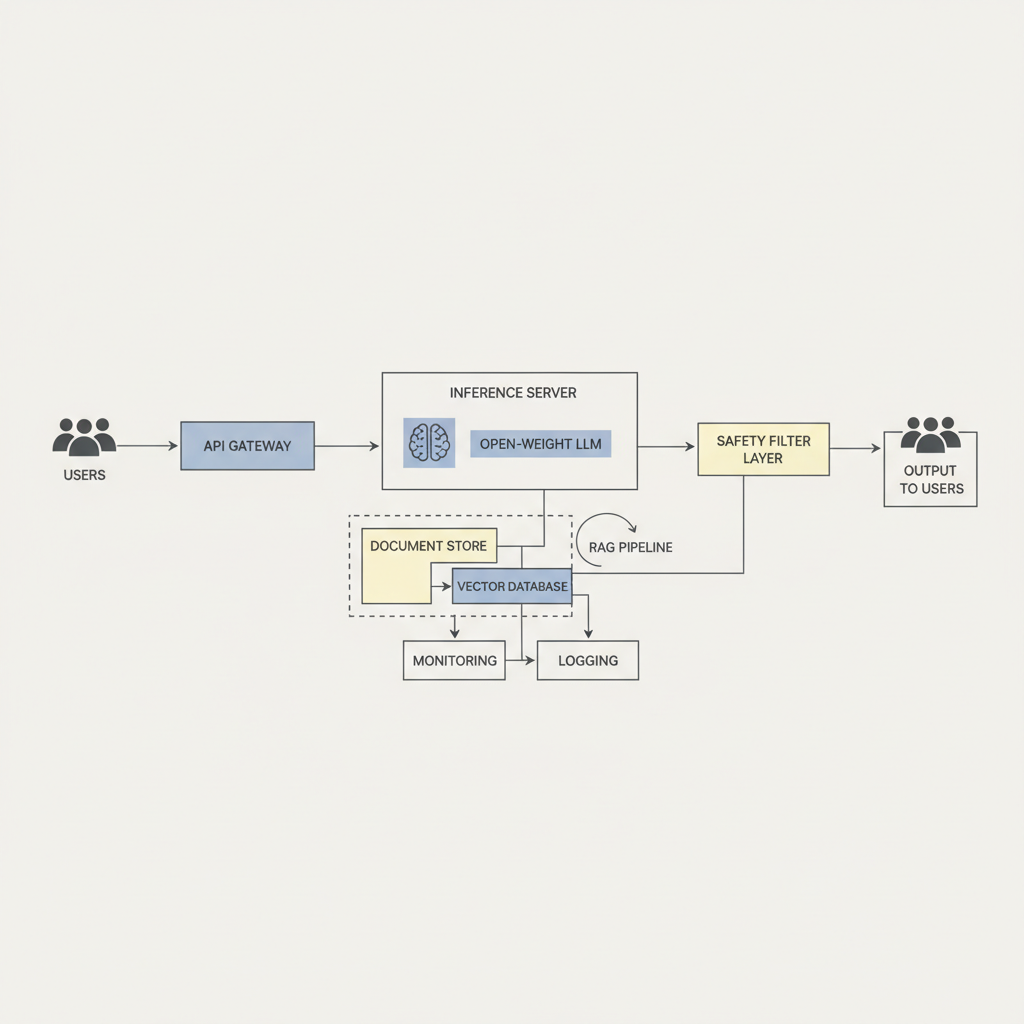
- Start with inference: Stand up open weight model inference behind an internal API, lock versions, log prompts safely.
- Add RAG before tuning: Many “knowledge gaps” are retrieval gaps, not model gaps.
- Quantize carefully: Lower precision can reduce cost, but can also change behavior, re-run eval.
- Then tune: Use supervised fine-tuning for style/format, consider preference tuning if you have reliable feedback signals.
- Productionize: Add rate limits, fallbacks, prompt injection defenses, and monitoring.
For open weight model deployment, the friction points are predictable: GPU availability, cold start time, concurrency limits, and observability. A “works on one A100” demo can still fail under real traffic and long context windows.
Safety, Governance, and Enterprise Readiness
Open weight model safety is not only about refusing harmful requests. It includes data handling, jailbreak resistance, and how you respond when the model is uncertain. Many teams also underestimate internal risks, like employees pasting sensitive customer data into a test prompt.
Minimum viable enterprise controls often include:
- Data policy: Redaction, retention limits, and access control for prompts and logs.
- Safety layer: Content moderation, policy prompts, and tool-use restrictions.
- Security hygiene: Artifact verification, dependency scanning, secrets management.
- Monitoring: Drift checks, abuse signals, latency and failure tracking.
- Human escalation: A path for edge cases, especially in regulated workflows.
According to CISA, organizations should manage cybersecurity risk through continuous assessment and mitigation. With open weights, you control the stack, which is empowering, but it also means you own more of the risk surface.
Key Takeaways and a Simple Next Step
If you are deciding whether to adopt Open-Weight Models, the most useful framing is: control vs. responsibility. You gain flexibility in inference, customization, and deployment options, but licensing diligence, evaluation discipline, and safety controls become your job.
- Don’t equate open weights with open source, treat licensing as a first-class requirement.
- Benchmark results are a hint, your task-specific evaluation is the decision tool.
- Deploying is a system problem, not a single-model problem, plan for monitoring and governance.
Action you can take this week: pick two candidate models, run a small but realistic evaluation suite on your own infrastructure, then write a one-page decision note that includes licensing constraints and operating cost estimates.
FAQ
Are Open-Weight Models free to use commercially?
Sometimes, but not always. Commercial rights depend on the exact license, and restrictions can be subtle, so it’s wise to route the license text through legal review before you commit.
What are good open weight model benchmarks to look at?
Look for benchmarks that match your modality and tasks, but treat them as directional. The more important piece is whether the model stays reliable on your own prompts, context lengths, and guardrails.
How do I choose an open weight LLM for enterprise deployment?
Start with licensing and infrastructure fit, then evaluate capability on a representative test set. Enterprise readiness usually comes down to reproducibility, monitoring, and a support plan, not just raw scores.
Is fine-tuning always better than RAG for domain knowledge?
Often no. If the issue is “it doesn’t know our latest policies,” retrieval tends to be safer and easier to update; fine-tuning makes more sense for consistent style, workflow constraints, or specialized formats.
What is the biggest hidden cost in open weight model inference?
Compute is the obvious one, but engineering time can rival it: serving stack tuning, reliability work, and repeated evaluation after every change in quantization, prompts, or guardrails.
How should we approach open weight model evaluation for safety?
Use a mix of policy tests, jailbreak attempts, and red-team style prompts aligned to your product. If your use case touches regulated decisions or sensitive user data, consider consulting qualified security or compliance professionals.
Can we deploy open-weight models on-prem?
In many cases yes, but confirm redistribution and on-prem rights in the license. Operationally, you also need a plan for hardware sizing, patching, and incident response.
If you’re trying to move from experimentation to a repeatable deployment path, it can help to map your requirements across licensing, evaluation, and infrastructure before picking a model, that small bit of structure usually saves weeks later.