
AI Hallucination is what people call it when a model responds confidently but the content is wrong, made up, or unsupported by the provided context. If you use LLMs for customer support, research summaries, legal drafts, or analytics, this isn’t a cute quirk, it’s a quality and risk problem.
The tricky part is that hallucinations rarely look like obvious nonsense. More often, they look like plausible facts, neat citations, or tidy explanations that match your expectations, which makes them easy to miss in a busy workflow.

This guide focuses on the practical questions teams actually ask: why ChatGPT hallucinates in certain situations, what patterns to watch for, how AI hallucination detection works in real products, and how to reduce AI hallucinations in LLMs using prompting, RAG, and evaluation habits that hold up under pressure.
What “AI Hallucination” Really Means (and What It Doesn’t)
In day-to-day usage, AI hallucination means the model outputs claims that are not grounded in training data in a reliable way, not supported by your prompt, or simply incorrect. It can be a wrong date, a fabricated policy, a fake quote, or a “citation-shaped” reference that doesn’t exist.
It helps to separate three common failure modes people mix together:
- Factual hallucination: incorrect statements about the world, like invented statistics or wrong product specs.
- Context hallucination: the model invents details that were never in your provided documents or conversation.
- Instruction drift: it follows a different goal than requested, then fills gaps with guesses.
You’ll also see the phrase LLM hallucination vs confabulation. Confabulation is often used in cognitive science to describe filling memory gaps with plausible stories; in LLM talk, it’s basically the same practical outcome: fluent output that isn’t anchored to verifiable sources. The label matters less than your mitigation plan.
AI Hallucination Causes: Why It Happens in Real Workflows
AI hallucination causes rarely come from a single “bug.” They’re usually a mix of model limits, ambiguous inputs, and product design choices that reward fluent completion.
- Next-token prediction, not truth-seeking: an LLM is trained to continue text patterns. When the prompt creates uncertainty, it still needs to produce a completion, and “sounding right” can win over “being right.”
- Missing or weak grounding: if the model has no access to your current, authoritative data, it may rely on vague priors or general patterns, which is risky for fast-changing domains.
- Ambiguous prompts and underspecified constraints: “Summarize the policy” without naming the policy version or source encourages assumptions.
- Long context and retrieval noise: even when you provide documents, irrelevant chunks or conflicting passages can push the model to synthesize something that isn’t actually supported.
- Overconfidence by design: many chat interfaces reward decisive answers. Unless your system prompts, UI, and policies encourage uncertainty, the model often won’t volunteer it.
According to NIST (National Institute of Standards and Technology), evaluating and managing risks in generative AI requires attention to validity, reliability, and safe use practices, which includes recognizing that models can produce inaccurate content in convincing forms.
AI Hallucination Examples You’ll Recognize Immediately
Teams often expect hallucinations to look bizarre. In practice, the most expensive ones look normal. A few AI hallucination examples that tend to slip into production:
- Fabricated citations: real-sounding journal titles, authors, and DOIs that don’t resolve.
- Policy and compliance “fill-ins”: the model invents what a regulator “requires” when asked for a summary.
- Product or API details: made-up parameters, outdated endpoints, or incorrect rate limits.
- Numbers with false precision: a confident percentage or revenue figure with no traceable source.
- Entity mix-ups: confusing two companies with similar names, or merging two people into one biography.
If you’re building internal tooling, the rule of thumb is simple: hallucinations cluster where verification is inconvenient and the model can still produce “a good story.”
How to Detect AI Hallucinations Before They Ship
AI hallucination detection is less about finding a magical classifier and more about creating friction where it counts: forcing traceability, requiring citations to be checkable, and scoring outputs against references.

Here are detection approaches that hold up in production settings:
- Attribution checks: require the model to quote or cite the exact supporting passage, then verify the passage exists and matches the claim.
- Claim extraction + verification: split output into atomic claims, then verify each claim via retrieval or a trusted database.
- Consistency checks: ask the model the same question with a different phrasing or force a structured answer, then compare for contradictions.
- Tool-based verification: route numerical, legal, medical, or policy claims to deterministic tools or approved sources rather than free-text generation.
- Human-in-the-loop review: still the most reliable for high-stakes domains, especially when reviewers have a checklist and source access.
A quick “risk sniff test” checklist
- High stakes: money movement, contracts, compliance, safety decisions.
- Freshness matters: anything that changes monthly or weekly.
- Hard to verify: long-tail facts, niche regulations, obscure technical specs.
- Prompt is vague: missing jurisdiction, dates, product versions, or source documents.
If two or more items apply, treat the output as a draft that needs grounding, not as an answer.
Mitigation: How to Reduce AI Hallucinations in LLMs
AI hallucination mitigation works best when you combine three layers: better inputs, better model behavior constraints, and better post-generation checks. No single tactic covers every failure mode.
- Make the task verifiable: ask for bullet claims with sources, not a single polished paragraph.
- Constrain the format: structured outputs (JSON, tables, fields) reduce room for improvisation.
- Use “refuse if unknown” rules: add instructions like “If the answer is not in the provided context, say you don’t know and ask for the missing source.”
- Separate drafting vs answering: let the model brainstorm, but require a second pass to justify each claim with evidence.
- Lower creativity where accuracy matters: in many systems this means tuning temperature or using a more conservative decoding setup.
According to OpenAI, model behavior depends heavily on prompting and system-level instructions, and developers should implement safeguards and evaluation for reliability, especially for high-impact uses.
RAG to Prevent Hallucinations: What It Fixes (and What It Doesn’t)
RAG to prevent hallucinations is popular because it gives the model something concrete to cite: your documents, policies, manuals, tickets, or database snapshots. When it works, RAG shifts the model from “guessing” to “answering from a library.”
But RAG is not a free pass. Hallucinations still happen when retrieval is wrong, the context window truncates key details, or the model overgeneralizes from partial evidence.
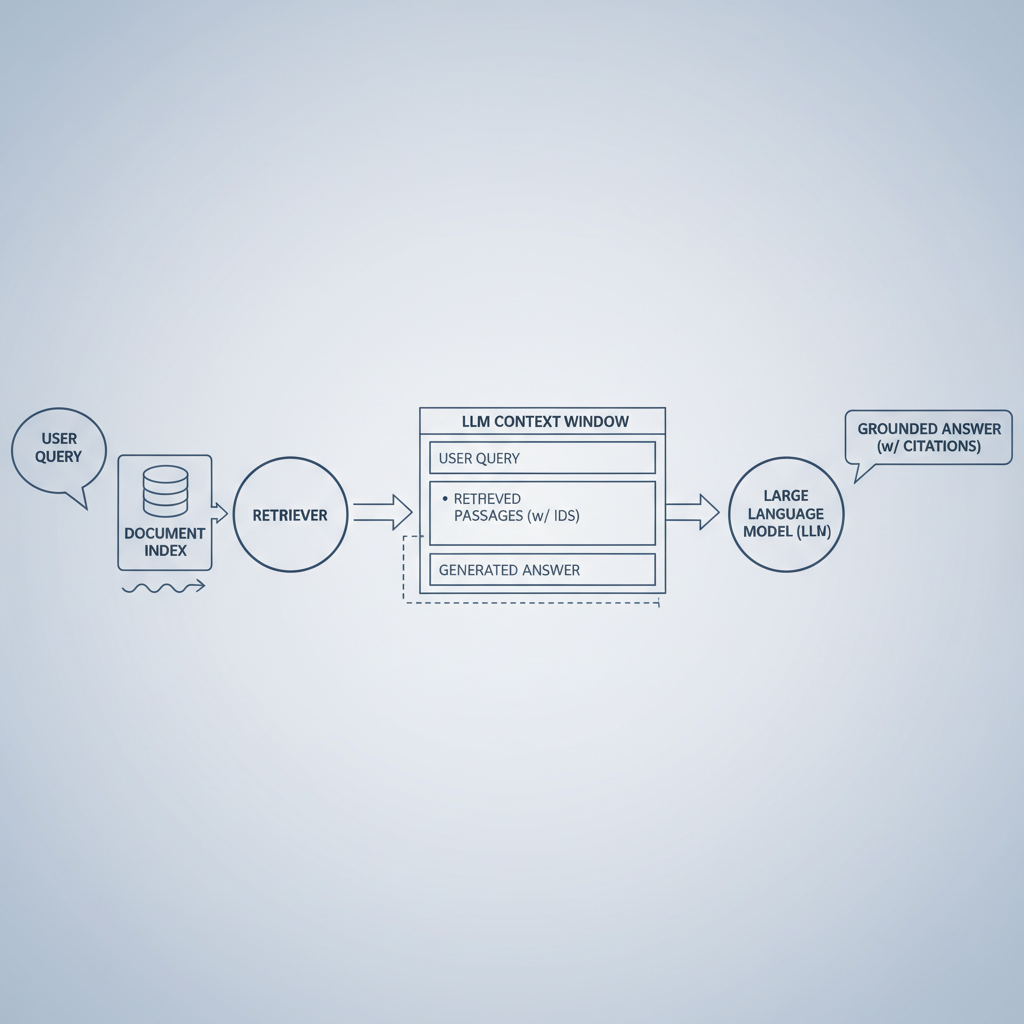
Practical grounding techniques for generative AI in RAG
- Optimize retrieval, not just generation: better chunking, metadata filters, and reranking often reduce errors more than prompt tweaks.
- Force citations: require citations for each key claim, and reject outputs with missing or duplicated citations.
- Quote-first answering: have the model extract supporting quotes, then write the answer only from those quotes.
- Coverage checks: if the query asks for “all exceptions,” ensure retrieval includes an “exceptions” section, not only the overview.
If you’re deciding between “bigger model” and “better retrieval,” many teams find retrieval improvements deliver more predictable gains for enterprise knowledge work.
Evaluating Hallucination Rates in LLMs (Without Fooling Yourself)
Evaluating hallucination rates in LLMs is where teams often get stuck, because hallucination is task-dependent. A model can look great on internal demos and still fail on edge cases, long-tail queries, or messy documents.
A practical evaluation plan typically includes:
- A representative test set: real queries, real documents, and the same failure modes you see in support tickets or analyst workflows.
- A clear definition of “hallucination” for your task: unsupported claim, incorrect claim, wrong citation, or missing refusal.
- Grading with references: reviewers must have the source of truth in front of them, otherwise you measure “confidence,” not accuracy.
- Segmented reporting: break down results by topic, document type, and query difficulty.
Common metrics teams track
| Metric | What it captures | Where it can mislead |
|---|---|---|
| Unsupported claim rate | How often answers include claims not backed by provided sources | Can look “good” if the model becomes overly cautious and refuses too much |
| Citation accuracy | Whether citations truly support the exact claim | Some systems cite relevant docs but not the right passage |
| Refusal quality | Whether the model declines when it should and asks for missing info | Over-refusal hurts usability and can mask retrieval gaps |
| Factual accuracy (gold set) | Correctness against a curated ground truth dataset | Gold sets age quickly in fast-changing domains |
According to NIST, trustworthy evaluation should be contextual and repeatable, which is another way of saying: measure what you actually deploy, not what looks clean in a lab prompt.
Common Misconceptions That Keep Hallucinations Alive
- “The model is lying.” Usually it’s not intentional deception, it’s pattern completion under uncertainty, but the user impact can feel the same.
- “RAG eliminates hallucinations.” RAG reduces some failure modes, while adding new ones like retrieval mistakes and citation laundering.
- “More tokens means better accuracy.” Longer answers can hide more unsupported details, especially when the prompt asks for “comprehensive” coverage.
- “A single benchmark score is enough.” Hallucinations are uneven; your toughest slice matters more than your average.
Conclusion: A Practical Way to Move Forward
AI Hallucination won’t disappear just because you switch models or write a clever prompt, but it becomes manageable when you treat accuracy as a system property: ground the model, constrain outputs, verify claims, and measure the right slices. That mix is what usually turns “impressive demo” into “reliable workflow.”
If you want an actionable starting point, pick one high-value use case, add citation requirements with source checks, then run a small evaluation set to see where the errors actually cluster, that tells you whether to invest next in retrieval, prompting, or review gates.